From Detection to Exploitation: How DCODX.AI Identified CVE-2026-22033
In this post, we disclose one of the first CVEs we identified after introducing DCODX.AI, our internal agentic whitebox pentesting tool we use to support our researchers and testers.
DCODX.AI leverages a GraphRAG-based architecture to:
Ground reasoning in application structure
Model entry points and reachability
Analyze privilege transitions
Identify composable weaknesses
Rather than asking whether a vulnerability exists, the system evaluates:
Can this weakness be reached?
Under which privilege context?
Can it be chained?
What is the maximal impact?
To test the capability of the agentic framework, we selected already tested open source repositories, to see whether we could uncover new vulnerabilities. We did.
The Target: Label Studio
Label Studio (https://github.com/HumanSignal/label-studio) is a widely adopted open-source data labeling and annotation platform used across the machine learning and AI ecosystem to prepare high-quality training data for models. It supports multi-modal annotation, including text, images, video, audio, and time-series, and provides flexible interfaces, custom workflows, and integration options that allow teams to tailor labeling tasks to their specific needs.

This versatility makes it a go-to tool for data scientists, research teams, and production ML pipelines alike, as it bridges the gap between diverse raw datasets and model training requirements.
Given its broad adoption, active community, and role in critical data workflows, Label Studio represents a compelling target for security analysis. Also other AI pentesting tools like XBOW had previously identified a few vulnerabilities in their codebase, so this made it the perfect test bench for our DCODX.AI.
The issue: CVE-2026-22033
The vulnerability, categorized as High (CVSSv4), originates from a persistent stored cross-site scripting (XSS) in the custom_hotkeys feature of the application. This is used to tailor keyboard shortcuts for common actions (like submitting an annotation or switching between tasks).
Any authenticated user can change the settings, and therefore inject arbitrary JavaScript code into the web interface.
Because this content is rendered in the templates/base.html template without adequate escaping, the browser interprets and executes the injected script when other users (including administrators) load any affected page.
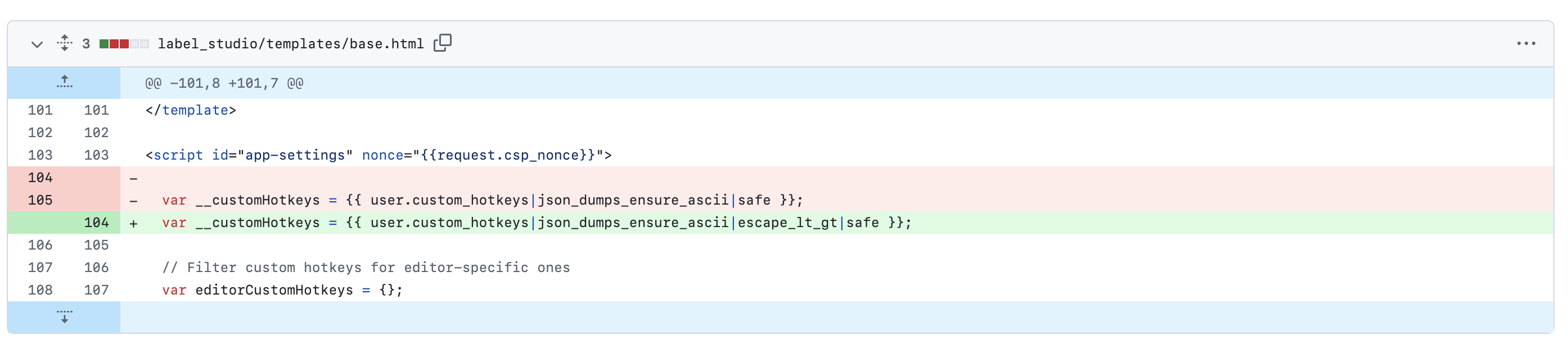
The vulnerable code is shown below, where the variable __customHotkeys uses the Django construct safe.
var __customHotkeys = {{ user.custom_hotkeys|json_dumps_ensure_ascii|safe }};
When we look at the description of the filter under the official Django documentation we can see that safe marks a string as not requiring any further HTML escaping prior to output. Also if we add escape after the filter safe that will make the XSS still possible.

On the server side, DCODX.AI also found that there is no escaping done on the custom_hotkeys fields.
This made is the perfect candidate for a stored XSS.
user.custom_hotkeys = serializer.validated_data['custom_hotkeys']
user.save(update_fields=['custom_hotkeys'])
But while is always nice to find XSS, we instructed DCODX.AI to always provide how a real exploitation would look like. This can give us the real impact of the vulnerability and help with prioritization.
To tackle this, we decided to ground the LLM’s reasoning in structured attack paths. Instead of treating every finding as a standalone alert, DCODX.AI builds a graph representation of the application’s entry points, data flows, privilege boundaries, and reachable execution paths. By anchoring the model’s analysis in this graph, we can instruct the LLM to:
Define clear security goals: e.g., “Can an unauthenticated user pivot to administrative capabilities?”
Trace a chain of reasoning across components: not just detect isolated patterns but determine whether an attacker could realistically traverse those patterns end-to-end.
Validate findings dynamically: by checking whether the proposed attack path executes against the real code logic or API behavior.
This combination of expert-directed goals and attack-path contextualization significantly reduces false positives and elevates the findings that truly represent exploitable risk.
So the tool was able to increase the severity of the stored XSS by using two additional factors:
Exposed API Token Endpoint: The application exposes the /api/current-user/token endpoint in the user’s browser context. Attackers can use this to fetch the victim’s API token via JavaScript.
Lack of Robust CSRF Protections: certain API endpoints do not require or properly validate CSRF tokens, enabling the injected script to perform privileged actions on behalf of the victim.
Together, these weaknesses mean that merely having an authenticated session (even at a low privilege level) allows an attacker to inject persistent client-side code, which in turn can steal API authentication tokens and perform unauthorized operations, effectively enabling full account takeover and unauthorized API access.
The full advisory on GitHub: https://github.com/HumanSignal/label-studio/security/advisories/GHSA-2mq9-hm29-8qch
The patch
The patch applied to the code mitigates the stored XSS vulnerability, making the attack void. We also teach this in our SCPy – DevSec Python Masterclass .
Conclusion
While recent advances in AI-based vulnerability detection, such as Claude Code Security are reshaping how we think about code vulnerabilities, automated reasoning alone is not sufficient. Tools like Claude reflect a significant evolution over traditional static analysis (SAST) by following data flows across files and identifying context-dependent issues that pattern matching would miss.
However, LLM-based scanners still produce false positives and findings that require real-world exploitability verification, and their reasoning must be grounded in context and domain expertise to avoid noise overwhelming human reviewers.
With DCODX.AI, grounding model reasoning in code and using GraphRAG to trace how data and control flows interact, we can filter out superficial or unreachable findings and highlight only those vulnerability paths that matter in practice.